|
Seismo-VLAB
1.3
An Open-Source Finite Element Software for Meso-Scale Simulations
|


|
|
Seismo-VLAB
1.3
An Open-Source Finite Element Software for Meso-Scale Simulations
|
|
Domain decomposition in Seismo-VLAB is employed to perform a parallel execution. Domain decomposition is carried out at the Pre-Analysis using METIS software. Here, the model domain (i.e., group of objects such as Node, Element, Material, Section, and Load) is divided so that the number of elements are almost uniform across processors.
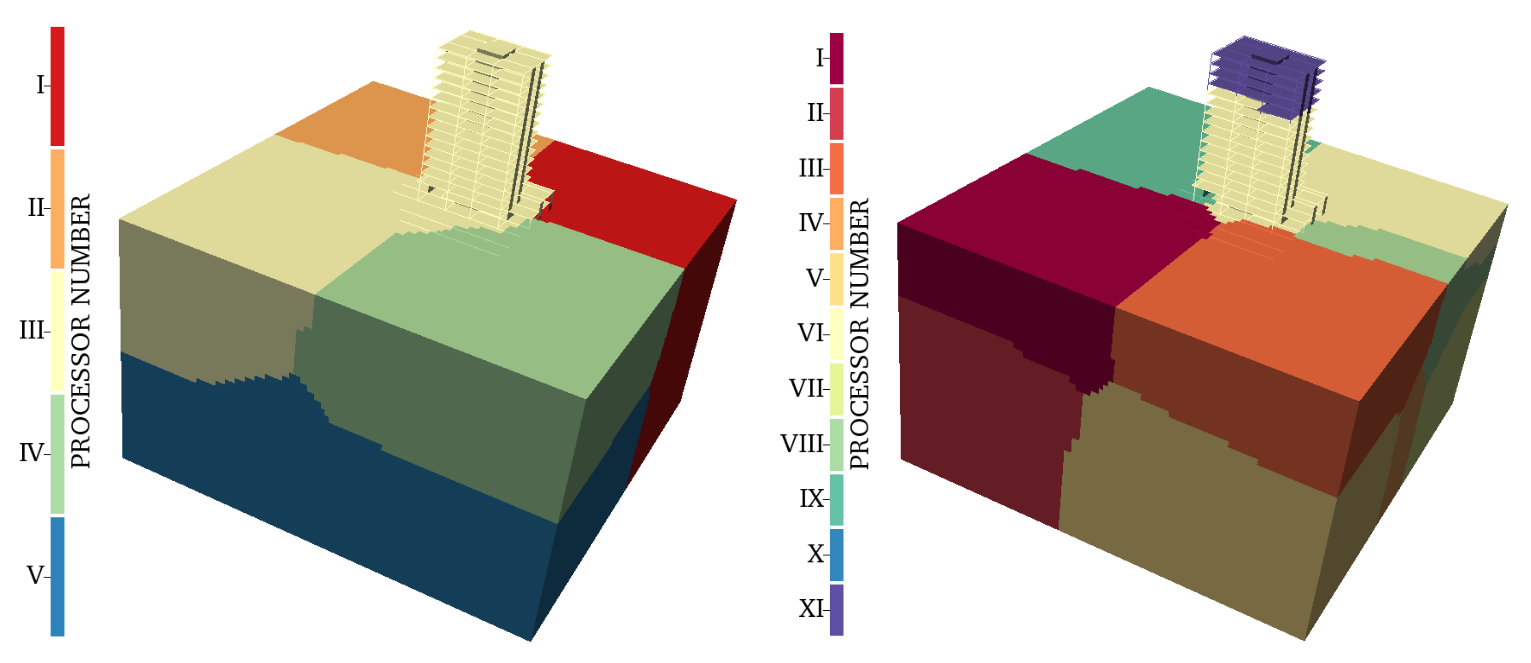
For parallel analysis, the user should be aware that required Entities in the Pre-Analysis must be defined in each processor for the Run-Analysis. For example, if the analysis option SVL.Options[ 'update' ] is employed, then when adding or removing elements for the next stage, Node, Material, Section, Element, and Constraint must be defined. We attempt to solve this problem in Partition.py in the CheckPartition() function, but some issues may arise if the mesh is updated/modified too much in each stage.
REFERENCE:
The DOMAIN DECOMPOSITION is performed at ./SVL/01-Pre_Process/Core/Partition.py. In this file, there are two functions:
Once the information of the mesh has been partitioned using METIS, the Entities dictionary is divided using the ./SVL/01-Pre_Process/Core/SeismoVLAB.py file. In this python script two function are essential:
Entities that belong to the partitionThe NUMBERING SCHEME (specified in Options['numbering']) is employed to map the degree of freedom number to the linear system equation to be solved. The number scheme available are Plain and CutHill-McKee. This also computes the amount of memory that PETSc matrices need to be allocated. Some of the functions defined are:
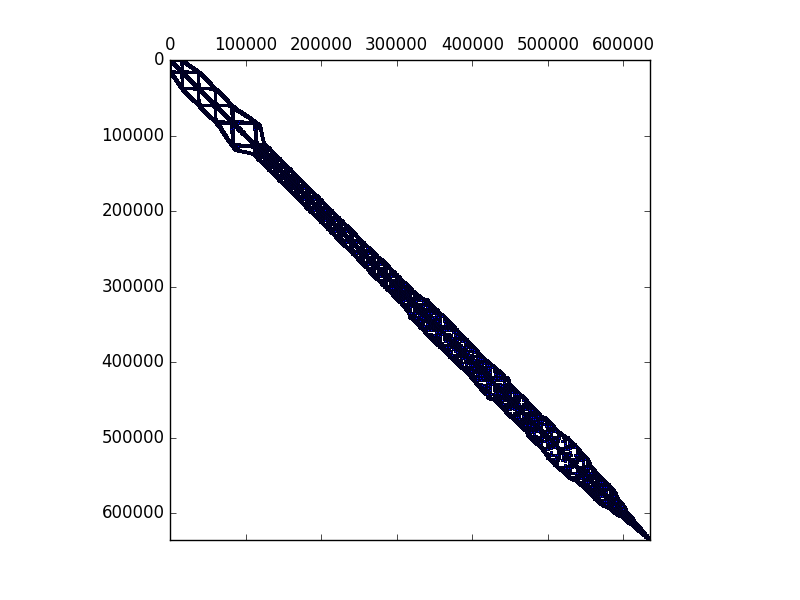
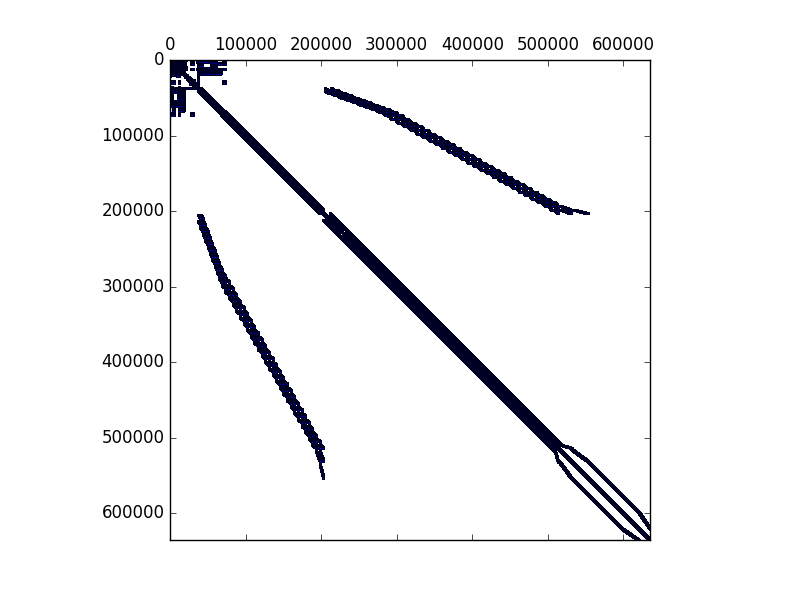
The File.#.$.json files located at the Partition folder are the result of the partitioned input files generated in Pre-Analysis. Note that the .$. represents the processor number and each one of these files contains a subdomain of the finite element model. Therefore, each .$. file is loaded depending on the processor number and no further care is taken in the Run-Analysis.
 1.8.13.
1.8.13.